Metodi di Machine Learning per la classificazione delle anomalie negli impianti di depurazione


Francesca Bellamoli
Production 4.0 ManagerMachine Learning e anomalie negli impianti di depurazione
I moderni impianti di trattamento delle acque reflue basano i loro processi biologici su sistemi di controllo avanzati, che hanno lo scopo di assicurare la conformità ai limiti di scarico e di ridurre al minimo il consumo energetico.
Tali controllori agiscono in base alle informazioni provenienti dalle sonde di processo installate in vasca. Le letture corrette delle sonde sono quindi particolarmente cruciali per un controllo avanzato del processo, in particolare per i controllori ad aerazione intermittente, che si basano su misurazioni in tempo reale di ammoniaca e ossigeno nelle vasche biologiche. Il corretto funzionamento di questi sensori è critico, ma non è sempre garantito a causa di sporcamenti del sensore, calibrazione errata o perdita progressiva di calibrazione, o problemi di trasmissione del segnale.
L’identificazione in tempo reale di questi eventi, in modo da poter attuare contromisure efficaci in tempi rapidi, risulta di grande interesse, ma di non facile realizzazione a causa dell’elevata complessità del processo e delle interazioni tra misure, controllore e processo biologico. La distinzione tra un semplice periodo di alto carico e una deriva verso l’alto della sonda dell’ammoniaca richiede l’analisi dei tracciati delle misure da parte di un operatore esperto, con grande utilizzo di tempo e risorse.
I sistemi di controllo sono solitamente associati ad una struttura di monitoraggio che raccoglie le misure dei sensori e i dati di funzionamento delle apparecchiature e li invia a un centro di controllo remoto, che raccoglie dati da diversi impianti per lunghi periodi di tempo. Questi dati rappresentano una risorsa importante che può essere utilizzata per l’estrazione di informazioni e per lo sviluppo di algoritmi di intelligenza artificiale in grado di identificare o prevedere le anomalie dei processi o dei sensori, guidando così le scelte degli operatori degli impianti senza un costante monitoraggio delle misure da parte degli operatori.
Per questo noi di Oscar Solutions abbiamo deciso di investire in un progetto di ricerca, che comprende un dottorato industriale, volto ad indagare l’utilizzo di metodi di machine learning per identificare le principali anomalie che può incontrare un controllore di processo ad aerazione intermittente. Questo progetto è ancora in corso e si è concretizzato in un articolo pubblicato su Journal of Environmental Management. Il modello sviluppato nell’articolo, poi ulteriormente perfezionato, è stato utilizzato per la costruzione di un Decision Support System che avvisi gli operatori nel momento in cui si verifica una delle anomalie prese in considerazione.
Bellamoli, M. Di Iorio, M. Vian, F. Melgani, Machine learning methods for anomaly classification in wastewater treatment plants, 2023, Journal of Environmental Management , volume 344
Problema e metodologia
Sebbene il rilevamento delle anomalie e la previsione delle serie temporali siano stati studiati in varie applicazioni per molti anni, il loro utilizzo in problemi in tempo reale come il trattamento delle acque reflue non è semplice a causa dei meccanismi complessi e interdipendenti che governano i processi di trattamento biologico e della natura rumorosa dei dati dei sensori. Esiste inoltre una concreta difficoltà nell’ottenere dati etichettati di lunghi periodi di tempo in impianti reali.
Gli andamenti dell’ossigeno, dell’ammoniaca e dell’energia sono infatti correlati tra loro sia dai processi biologici che avvengono nella vasca sia dall’azione del controllore stesso. Una misurazione errata delle sonde di ammoniaca o di ossigeno influenza l’azione del controllore, che a sua volta modifica l’ammoniaca e l’ossigeno effettivi in vasca, rendendo così molto difficile la corretta identificazione delle anomalie, anche per un tecnico esperto.
Il nostro studio riguarda un gruppo di impianti di trattamento delle acque reflue situati in diverse parti d’Italia, tutti operanti con un processo di nitrificazione-denitrificazione ad aerazione intermittente effettuato tramite il controllore di processo Oscar®.
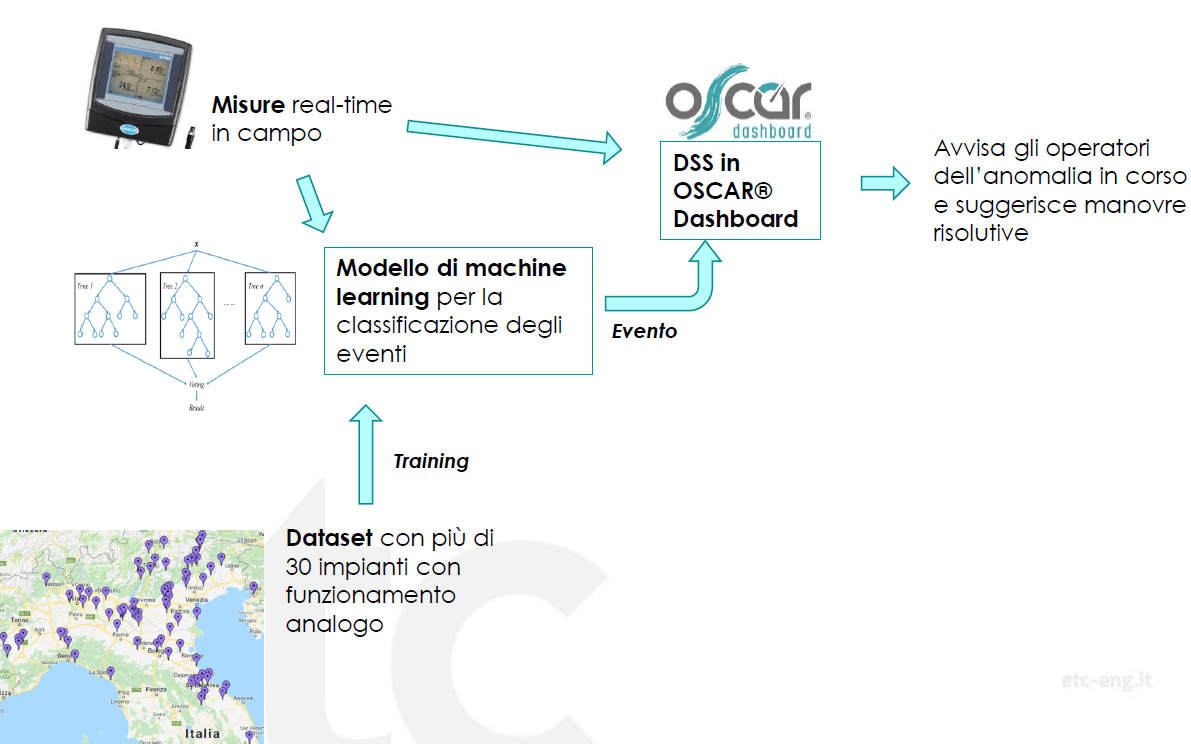
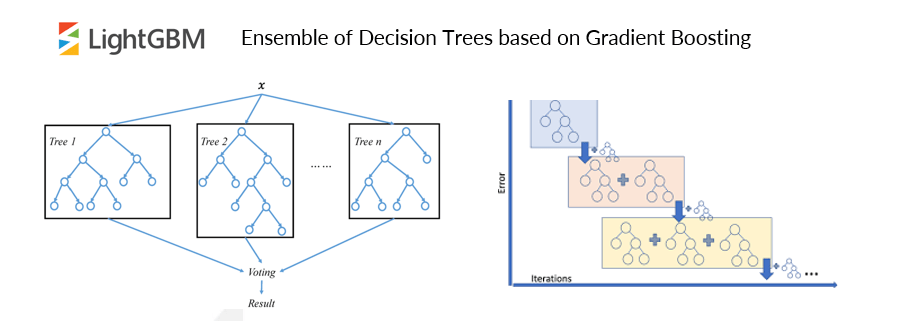
Abbiamo implementato algoritmi di classificazione sia binaria che multiclasse, confrontandoli attraverso una rigorosa procedura di validazione che include un test su un dataset indipendente (non utilizzato durante l’addestramento e l’impostazione degli iperparametri degli algoritmi). I metodi di classificazione esplorati sono support vector machine, multilayer perceptron, random forest e due metodi di gradient boosting.
Ogni algoritmo prende in input solo le misure di ossigeno, ammoniaca e consumo energetico nella sezione biologica di un impianto di depurazione: queste misure sono comunemente disponibili negli impianti con questo tipo di controllore, rendendo così l’algoritmo sviluppato facilmente applicabile a impianti reali.
L’obiettivo finale era quello di trovare un algoritmo che garantisse l’identificazione della maggior parte degli eventi anomali con una precisione sufficiente a minimizzare i falsi allarmi.
Le anomalie considerate sono le seguenti:
- Offset o deriva della sonda dell’ammoniaca: tali eventi sono problematico perché il controllore regola su un’ammoniaca che è più alta o più bassa di quella in vasca, aerando troppo poco o troppo rispetto a quanto realmente necessario.
- Sporcamento delle sonde di ossigeno: tale evento determina uno spreco di energia per cercare di raggiungere il set-point, quando la misura non ci può arrivare a causa dello sporcamento.
- Grandi e rapide variazioni del carico influente: in questi casi la reazione del controllore spesso non è abbastanza rapida. Inoltre, tali eventi possono essere facilmente confusi con i precedenti.
Validazione e risultati
Il metodo di addestramento del modello e il protocollo di valutazione sviluppato sono molto rigorosi e prevedono la selezione degli iperparametri e la valutazione di alcune metriche di performance attraverso una cross-validation su un primo dataset e un test finale su un secondo dataset contenente impianti e periodi completamente diversi dal primo. Particolare attenzione è stata data alla definizione di una metrica di performance che possa valutare se ogni evento viene identificato con una tempistica utile per l’operatore dell’impianto di depurazione (entro un tempo massimo di 48 ore).
I modelli che hanno dato i migliori risultati sono stati gli algoritmi di ensemble basati su alberi, in particolare quelli che utilizzano il gradient boosting. Il recall (percentuale di eventi individuati) ottenuto va da un 62% dell’algoritmo multiclasse testato sul Dataset 2 al 92% dell’algoritmo binario sul Dataset 1.
Considerando che un algoritmo, per essere utile agli operatori degli impianti di depurazione, dovrebbe fornire almeno il 75% di recall con il 50% di precisione, l’uso di metodi di machine learning per il rilevamento delle anomalie negli impianti di depurazione si è rivelato molto efficace anche quando applicato a dati nuovi.
Il modello migliore tra quelli testati è stato quindi allenato su tutti i dati a disposizione, ulteriormente migliorato, e implementato nell’infrastruttura di calcolo di Oscar Dashboard® come Decision Support System. Tale modello viene inoltre utilizzato per aiutare gli operatori del service nella raccolta di nuovi dati etichettati per ampliare il dataset. Si prevede di ri-allenare periodicamente il modello sfruttando i nuovi dati raccolti.
Contattaci
Questo articolo ti ha fatto venire voglia di saperne di più? Contattaci per capire se questi sistemi sono applicabili al tuo impianto!